

At VendueTech, our mission is to turn complex, fragmented public auction information into reliable, machine-readable intelligence that can be used safely, consistently, and at scale across Europe.
Public auction datasets are inherently challenging:
they are heterogeneous, multilingual, structurally inconsistent, and evolve continuously over time. Making this data usable for analytics, decision-making, and downstream AI systems requires more than off-the-shelf tooling—it requires deep technical R&D, careful validation, and production-grade engineering.
To tackle this problem systematically, VendueTech partnered with EDIH CROBOHUB++ and the FER TakeLab at the FER, using the Test-Before-Invest (TBI) framework.
This collaboration allowed us to move from research hypotheses to deployed, production-ready AI infrastructure—without premature scaling risk.
Why Test-Before-Invest Is Critical for Serious AI Infrastructure
The Test-Before-Invest model enables technology companies to:
- Experiment on real, production-like data
- Validate architectural decisions under expert supervision
- Stress-test models and pipelines before committing long-term resources
- Reduce technical, operational, and financial risk
For VendueTech, TBI provided the structure needed to validate one of the hardest problems in applied AI today:
Consistent, schema-faithful extraction of structured information from complex, semi-structured public data—across jurisdictions, languages, and formats.
Phase 1: Understanding the Data Reality
The first phase focused on data characteristics and constraints rather than tooling.
Together with FER researchers, we analyzed:
- Structural variability of auction datasets across sources and regions
- Common failure modes of traditional extraction approaches
- Requirements for repeatability, auditability, and downstream compatibility
- Alignment with legal, ethical, and data-governance standards
Key insight
Any solution had to preserve semantic structure (key–value relationships, nested attributes, temporal fields) exactly as presented, without heuristic loss or uncontrolled normalization.
This immediately ruled out generic text-conversion pipelines.
Venduetech - TBI report - TBI1 …
Phase 2: Why Generic Extractors Fail—and Domain-Tuned LLMs Succeed
The second phase evaluated whether modern AI models could reliably transform complex inputs into strictly structured outputs suitable for automated processing.
We tested multiple approaches to structured extraction and found consistent limitations:
- Loss of field boundaries
- Inconsistent formatting across runs
- Poor handling of nested or contextual attributes
- Inability to enforce strict output schemas
The Turning Point: Instruction-Tuned LLMs
Example input (just the beginning of the document):
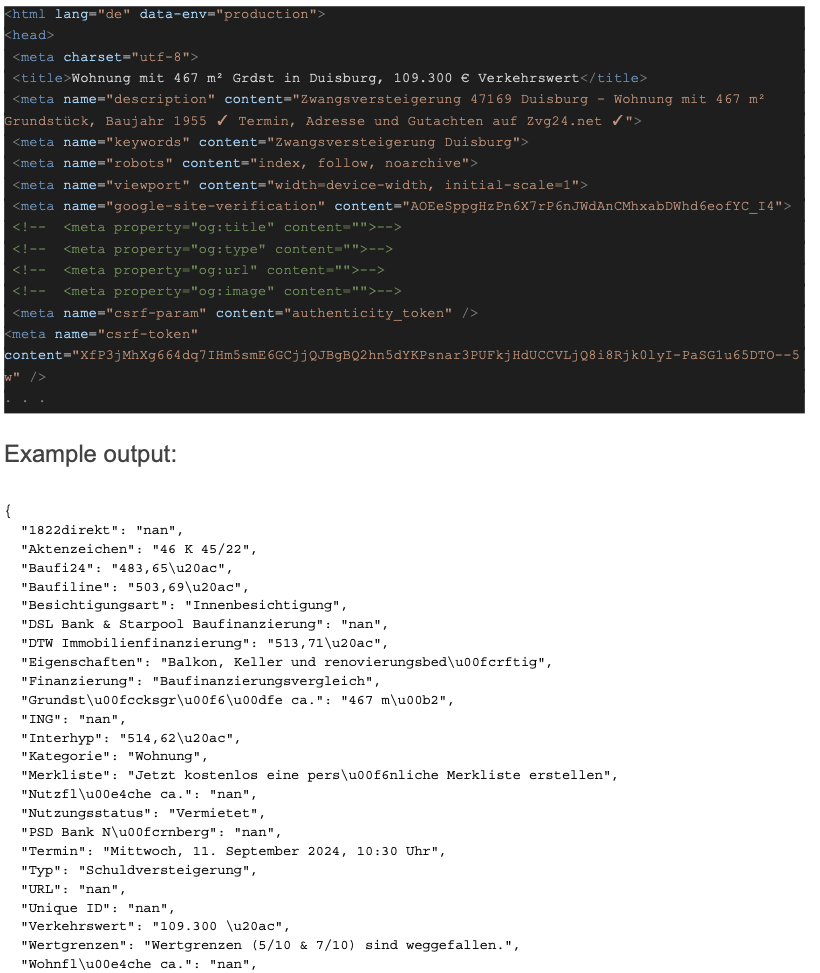
In collaboration with TakeLab, we designed and evaluated instruction-tuned large language models trained specifically to map domain-specific inputs into deterministic, key-value outputs.
Two strategies were compared:
- Prompt-based inference on cleaned representations
- Instruction-tuning compact LLMs using QLoRA
Outcome
Instruction-tuned models significantly outperformed prompt-only approaches, achieving near-deterministic output fidelity under exact-match evaluation—an essential property for production systems.
This phase validated a core architectural principle of VendueTech:
If output consistency matters, domain-specific fine-tuning beats generic prompting—every time.
Venduetech - TBI report - TBI2 …
Phase 3: Turning Research into Production Infrastructure
High extraction accuracy alone is insufficient without operational robustness.
The final TBI phase focused on deploying the solution in realistic conditions, emphasizing:
- Model efficiency and resource optimization
- Deterministic JSON outputs enforced by schema
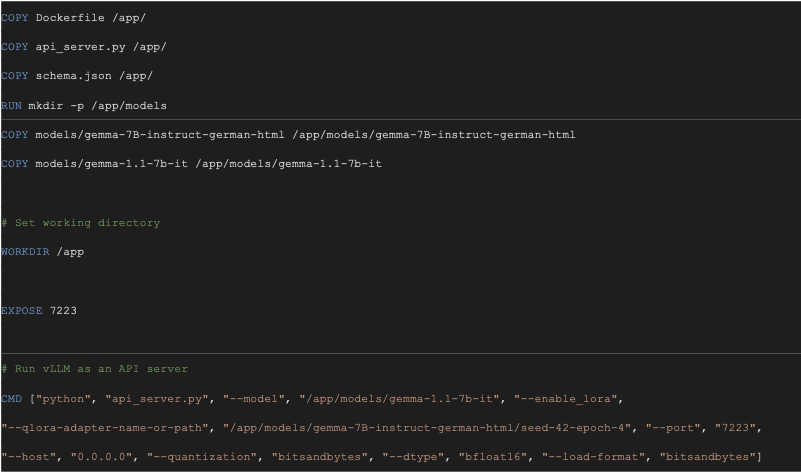
- Containerized deployment for reproducibility
- API-driven integration with downstream systems
The Production Pipeline
Working closely with TakeLab, we delivered a fully containerized AI service with:
- Input normalization and preprocessing
- A quantized, domain-tuned LLM (4-bit QLoRA)
- Constrained decoding to enforce strict JSON schemas
- Automatic validation and post-processing
- High-throughput inference using vLLM
All components are encapsulated in Docker, enabling:
- Predictable deployments
- GPU-efficient scaling
- Infrastructure portability across environments
The result is a system where complex public data can be transformed into production-ready, schema-valid JSON via a simple API, without sacrificing precision, control, or auditability.
Looking Ahead
The work delivered through the TBI collaboration forms the backbone of VendueTech’s broader AI roadmap.
Future directions include:
- Cross-domain generalization
- Multi-document reasoning
- Temporal intelligence over auction lifecycles
- High-performance model training and evaluation
This is how Bidsale®, VendueTech’s auction intelligence platform, is being built:
quietly, rigorously, and with infrastructure-level ambition.


